世界のコンテンツ検出市場(~2029):検出種類別、コンテンツ 種類別、エンドユーザー別、地域別分析レポート

市場概要
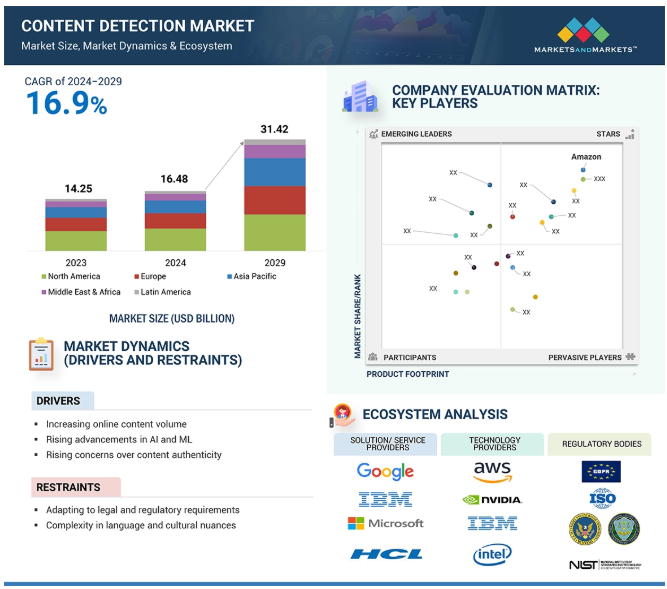
コンテンツ検出市場は、2024年には164.8億米ドル、2029年には314.2億米ドルに達すると予測され、予測期間中の年間平均成長率(CAGR)は16.9%である。特にソーシャル・メディア・プラットフォームにおけるユーザー生成コンテンツの増加、著作権侵害に対する懸念の高まり、不快なコンテンツや違法コンテンツの規制を求める政府機関からの要請。さらに、サイバー上の危険性の増加、リアルタイムのコンテンツモデレーションの必要性、動画やストリーミングサービスの増加により、効率的なコンテンツ検出システムの必要性が高まっている。特に、ディープフェイク検出、コンテンツ検証のためのブロックチェーン、人工知能ソリューションとの関連で、市場は拡大する可能性が大きい。
ジェネレーティブAIの出現は、既存の検出戦略を改善するだけでなく、コンテンツ検出業界を破壊している。メディア・フォレンジックを目的としたGANやトランスフォーマーなどの高度なAIアーキテクチャの導入は、ディープフェイクやフェイクニュース、改変された写真の背後にある文脈や意図をより的確に把握できるため、特に効果的である。さらに、このテクノロジーはリアルタイムのモデレーション(特にソーシャルメディアやライブストリーミングプラットフォームの例では、不適切な画像や動画にフラグが立てられる割合が大幅に増加する)を進めるのに役立つ。これに加え、ジェネレーティブAIは、コンテンツが改ざんされたことを検知するツールを提供することで、コンテンツ制作を支援する。また、すでに検証された情報のデータベースと事実を比較することで、架空のコンテンツとの戦いを支援する。最後に、合成データセットの使用を通じて、ジェネレーティブ・アルは既存の検知システムをより良く訓練し、新たな高度な脅威に対してより堅牢にする。また、AIシステムによって生成されたコンテンツは武器化される可能性があり、コンテンツ制作者とコンテンツモデレーターの間の軍拡競争に拍車をかけるため、道徳的な問題も提起される。AIをコンテンツ監視に応用することで、プライバシーに関するリスクも生じる。加えて、生成的なAlを使用し、検出が困難なコンテンツ作成のための戦略もあり、コンテンツモデレーションのための新たな戦略が必要となる。生成的Alはコンテンツ検出を強力にする一方で、コンテンツ作成の状況の変化に関係なく、継続的な有効性を確実に維持するために、より創造的な戦略の必要性が生じる。
誤報、操作されたメディア、ディープフェイクが著しく増加しているため、コンテンツの信憑性を判断するツールが必要である。ソーシャルメディアの広範な利用は、一般大衆を誤解させ、認識を歪めるような誤った物語や情報を生み出す上で、重要な役割を果たすことが多い。その結果、政府やその他の機関は、データを自動的に検証し、疑わしい情報源やコンテンツにフラグを立てることができるツールを探すよう求められている。また、ディープフェイク技術の開発は、偽物でありながら本物に見える音声や映像コンテンツの使用によってもたらされる極端な損害のため、そのようなツールの使用にも疑問を投げかけている。また、公共の場にいる個人も企業も、改ざんされた、あるいは非同意的な画像、言葉、商品を検索するコンテンツ検出ツールの助けを借りて、自社のイメージを保護することに関心を持っている。加えて、欧州連合(EU)が導入したデジタルサービス法(DSA)のような規制的イニシアチブの高まりも、コンテンツ管理の重要性を浮き彫りにし、コンテンツリスクを軽減し、透明性を高める手段を調達することへのテクノロジー企業への期待を高めている。一方、ユーザーの間で検証された情報に対するニーズが高まっていることから、ソーシャルメディアやニュースのプラットフォームは、信頼構築のために検証済みコンテンツのラベルを発行するようになっている。高度なAlと機械学習によって強化された検出ツールは、メタデータの異常やコンテンツの改変を発見するための視覚的不整合などの指標を取り入れることで、より洗練されたものとなっている。要するに、このような問題の増大により、政府、組織、デジタル・プラットフォームは、コンテンツ検出のためのソリューションに注目せざるを得なくなっており、市場におけるソリューションの革新と受容の必要性が生じている。
コンテンツ検出市場が直面しているのは、法律や規制の枠組みを遵守する必要性である。なぜなら、これらの要因は場所によって大きく異なり、常に変化しているからである。例えば、欧州連合(EU)傘下の数カ国における一般データ保護規則(GDPR)のような異なるデータ保護規制や、他の数カ国における検閲規制の実施は、コンテンツ検出システムの導入を非常に困難にしている。また、ユーザー生成コンテンツ・ポリシーに関連する制約もあり、単純化して言えば、システムはユーザーの権利に対して特定のコンテンツをモデレートするというポリシーの中間点を見つけなければならないということだ。グローバル企業は、現地の法律を遵守したり、特定の既存または新規の規制の範囲内で現地の業務を遂行しなければならない。コンテンツ検出システムは、効率的に使用するために、未分化の多種多様な法制度に対応できることが期待されているが、これは高価で時間のかかる新たな適応を必要とする。加えて、オリジナルコンテンツの保護と曖昧な検閲ポリシーへの懸念が、法的環境をより複雑なものにしており、コンテンツ検出市場のプレーヤーにとってさらなる困難を生み出している。
コンテンツ検出市場においてコンテンツモデレーションサービスのニーズが高まっているのは、これらのプラットフォームがすべて安全で、モデレートされ、魅力的なオンラインプレゼンスを持っているからである。ソーシャルメディア、ライブストリーミング、リアルタイムのコミュニケーションの増加に伴い、ユーザーだけでなく、ブランドの評判も守るために、有害、虐待的、あるいは違法なコンテンツを迅速に検出、特定、対処できることが求められるようになりました。また、EUのデジタルサービス法に見られるように、コンテンツの削除命令が規制されたことで、コンテンツ主導型のプラットフォームは、法律に準拠してテキストや画像をリアルタイムで分析できるAlテクノロジーを統合することが必須となり、さもなければ重い制裁を受けることになる。繰り返しになるが、現在では、瞬時にコンテンツを管理することで、ブランドを信頼している顧客に迷惑をかけることによるリスクを軽減し、忠誠心を促進することができる。広告が不快なコンテンツの近くに表示されないようにすることで、広告主を保護します。近年、人工知能システム、特に言語学とコンピュータグラフィックスで使用される既存技術の向上により、膨大な量のデータを短時間で処理する速度があるため、リアルタイムでコンテンツをモデレートすることが容易になっていることに加え、ソーシャルネットワーク、ビデオ会議、オンラインゲーム、eスポーツのデジタル分野でも、このようなリアルタイム技術の需要と利用が増加していることが要因となっている。現在では、そのほとんどが何らかの形で自動モデレーションを奨励し、エスカレーションが困難なケースでは人間が介入する可能性があるため、モデレーション・プロセスが洗練され、圧倒的なリソース・コストをかけずにリアルタイム・モデレーションが実用化されている。
有害コンテンツの検出市場は、ソーシャルメディア、ストリーミング・サービス、ユーザー生成コンテンツ・サイトにおけるデータの急激な増加により、大量のコンテンツを管理することが大きな課題となっている。このようなコンテンツ検出システムは、リアルタイムで処理されるテキスト、画像、動画の数など、データ量の増加に伴って規模が拡大することが予想され、そのためには多くのコンピューティング・パワーと優れたインフラが必要となる。大量のデータを扱う状況では、精度を維持することがさらに難しくなるため、偽陽性や偽陰性の可能性が高まります。また、データのローカライゼーションやデータ・プライバシー・コンプライアンスの観点から、データベースのサイズを管理する必要があるため、運用上の問題もある。コンテンツモデレーションに関しては、脅威となるコンテンツへの迅速な対処を求めるプラットフォームが存在するため、リアルタイム処理は複雑であり、複雑なアル・モデルと高速処理が求められる。そのため、定期的なEMトレーニングやモデルのアップグレードに加え、リソースの割り当てや運用コストの削減を余儀なくされる。また、コンテンツは多くの場合インタラクティブであり、様々なシステムや複雑さの中で設計することが可能であるため、異なる編集可能な環境間でコンテンツ検出やコンテンツブロックの基準を同じように維持するという課題もある。
TSソーシャル・メディア・プラットフォームは、テキスト、画像、動画、音声にわたる不適切、有害、またはコンプライアンス違反のコンテンツを特定するために、コンテンツ検出技術を利用している。Twitter、Facebook、Reddit、Instagramなどのプラットフォームは、ソーシャルネットワークを形成して情報を共有・公開することで、人々が世界にアクセスし、つながることを可能にする人気のある広く利用されているプラットフォームである。様々なソーシャルメディア・プラットフォーム上の膨大な量のユーザー生成コンテンツ(UGC)を考慮すると、ソーシャルメディア上の有害なコンテンツの検出とモデレーションが最も重要になっている。国家犯罪記録局(NCRB)のデータによると、ソーシャルメディア上でのサイバー犯罪が増加している。インドでは、ソーシャルメディア上のフェイクニュースが578件、女性や子供に対するネットいじめが972件、偽プロフィールの事件が149件あったとTimes of India 2020で報告されている。ソーシャルメディア・プラットフォーム上でコンテンツが公開されると、公開されたコンテンツが有害か無害かを識別または分類するために検出される。人工知能(AI)は、機械学習(ML)アルゴリズムと自然言語処理(NLP)を通じて、ソーシャルメディア上の有害なコンテンツを自動検出するための新たなツールとして登場した。これらのAIベースの検出方法の使用は、コンテンツのフラグを立てる際に人間のモデレーターを支援する。
ビデオコンテンツの検出は、好ましくない、海賊版、またはAl-generatedコンテンツを検出するためにオーディオビジュアルコンテンツを分析することである。コンピュータ・ビジョンや機械学習アルゴリズムのような技術は、動画ストリームにおけるヌード、暴力、ヘイトスピーチの検出に積極的に参加している。この技術は、要求されるコミュニティ・ガイドラインに準拠するため、ストリーミング・プラットフォームに広く採用されている。さらに、グーグルはYouTubeと協力して、人工知能を使って生成された顔や動画を検出する方法を学習できる一連の技術を開発している。同社は2025年初頭に初期段階のパイロット・プログラムを予定しており、現在も技術を改良中だ。短い動画を扱う最新の新興プラットフォームが台頭する中、動画検出ソリューションは、地域社会の規範を遵守する場を開放する上で重要になっている。
アジア太平洋地域のコンテンツ検出市場は、デジタルコンテンツ消費の増加、政府の政策、人工知能や機械学習技術の発展により、急速なペースで成長している。特に中国、インド、東南アジア地域など、インターネットやモバイルの利用が目覚ましい勢いで増加している国々で、このようなツールの利用について詳しく話す。ソーシャル・ネットワーキング・サイト、eコマース・ウェブサイト、OTTプラットフォームは、それぞれ顧客エンゲージメント、製品偽造防止、著作権保護を管理するためにコンテンツ・モデレーションを利用している主なクライアントである。しかし、多言語コンテンツの取り扱い、データ保護、全体的な実行コストなどの問題には、まだ対処する必要がある。需要は主にグーグル、マイクロソフト、アマゾンのような国内外の大手企業がそれぞれ満たしているが、一方で革新的な新企業が市場動向を踏まえて構築している。

2024年11月、ClarifaiはBerkeley Artificial Intelligence Research (BAIR) Open Research Commonsに参加し、AIイノベーションを推進します。クラリファイの参加は、特にコンテンツモデレーション、視覚的・クロスモーダル類似検索、オープンボキャブラリーによる小物体の検出と追跡などの分野で、最先端のAIを推進するBAIRのコミットメントを強化するものです。
2024年9月、Microsoft社は「Correction(修正)」と呼ばれる新機能を発表した。同社によると、AIが生成した誤った情報を自動的に検出し、修正するものだという。この新ツールはマイクロソフトのAzure AI Content Safety APIの一部である。
2024年9月、Tata Consultancy Services(TCS)はGoogle Cloudとの提携を拡大し、企業のサイバー耐性を強化することを目的とした、AIを活用した2つの新しいサイバーセキュリティ・ソリューションを発表した。新しいソリューションには、TCS Managed Detection and Response(MDR)とTCS Secure Cloud Foundationが含まれる。
2024年3月、Huawei CloudはYASH Technologiesと提携した。この戦略的パートナーシップは、MENA地域におけるクラウドコンピューティングとAIソリューションの提供に焦点を当てている。この提携は、ファーウェイのAIアプリケーションを活用して企業のデータ分析と機械学習機能を強化することを目的としており、より広範なAIイニシアチブの一環としてコンテンツ検出技術に影響を与える可能性がある。
主要企業・市場シェア
コンテンツ検出市場は、幅広い地域で存在感を示す少数の主要プレーヤーによって支配されている。コンテンツ検出市場の主要プレーヤーは以下の通りである。
Microsoft (US)
Google (US)
Amazon (US)
Alibaba Cloud (China)
IBM (US)
HCL Technologies (India)
Huawei Cloud (China)
Wipro (India)
Accenture (Ireland)
Clarifai (US)
Cogito Tech (US)
TaskUS (US)
Cognizant (US)
Proofpoint (US)
Concentrix (US)
SunTec.ai (US)
Besedo (Sweden)
ActiveFence (US)
Sensity (Netherlands)
Hive (US)
QuillBot (US)
Originality AI (Canada)
Imerit Technology (US)
Dataloop (Israel)
WebPurify (US)
【目次】
はじめに1
1.1 調査目的
1.2 市場の定義 包含と除外
1.3 市場スコープ 市場セグメンテーション 対象地域 考慮年数
1.4 通貨
1.5 利害関係者
調査方法2
2.1 調査データ 二次データ – 二次情報源 一次データ – 専門家への一次インタビュー – 主要一次インタビュー参加者リスト – 一次プロファイルの内訳 – 一次情報源 – 主要業界インサイト
2.2 市場分類とデータの三角測量
2.3 市場規模の推定 ボトムアップアプローチ トップダウンアプローチ
2.4 リサーチの前提
2.5 リスク評価
2.6 制限事項
エグゼクティブサマリー 3
プレミアム・インサイト 4
4.1 コンテンツ検出市場における魅力的な機会
4.2 コンテンツ検出市場、提供製品別
4.3 コンテンツ検出市場、検出種類別
4.4 コンテンツ検出市場、コンテンツ種類別
4.5 コンテンツ検知市場:エンドユーザー別
4.6 北米:コンテンツ検知市場:オファリング別、国別(2024年)
4.7 アジア太平洋地域:コンテンツ検知市場:提供製品別、国別(2024年)
5.1 はじめに
5.2 市場ダイナミクス 推進要因 阻害要因 機会 課題
5. 3 業界動向 コンテンツ検知の簡単な歴史 顧客のビジネスに影響を与えるトレンド/混乱 価格分析-主要企業の平均販売価格動向(提供物別)-指標価格分析(コンテンツタイプ別) 供給/バリューチェーン分析 エコシステム/市場マップ 技術分析-主要技術-補完技術-隣接技術 特許分析-主要特許のリスト ケーススタディ分析 2024-2025年の主要会議/イベント コンテンツ検知ツールを導入するためのベストプラクティス、 規制情勢-規制機関、政府機関、その他の組織-主な規制 ポーターの5力モデル-新規参入の脅威-代替品の脅威-買い手の交渉力-供給者の交渉力-競合の激しさ 主な利害関係者と購買基準-購買プロセスにおける主な利害関係者-購買基準 投資と資金調達のシナリオ AI/ジェネAIがコンテンツ検出市場に与える影響
コンテンツ検出市場:提供製品別
6.1 導入 コンテンツ検出市場:提供製品別 ドライバー
6.2 ソリューション
6.3 サービス
コンテンツ検出市場:検出種類別
7.1 導入 コンテンツ検出市場:検出種類別 推進要因
7.2 コンテンツモデレーション
7.3 AI生成コンテンツ検知
7.4 盗用検知
7.5 その他の検知タイプ(著作権・知的財産権侵害、ネットいじめ)
コンテンツ検出市場、コンテンツ種類別
8.1 導入 コンテンツ検知市場、コンテンツ種類別 ドライバー
8.2 ビデオ
8.3 テキスト
8.4 画像
8.5 音声
コンテンツ検出市場、エンドユーザー別
9.1 導入コンテンツ検出市場:エンドユーザー別:ドライバー
9.2 ソーシャルメディア・プラットフォーム
9.3 ストリーミング・コンテンツ共有プラットフォーム
9.4 小売・eコマース
9.5 ゲームプラットフォーム
9.6 その他のエンドユーザー
…
【本レポートのお問い合わせ先】
www.marketreport.jp/contact
レポートコード:TC 9252